Summary
In my previous post, I referenced several great videos covering the transformer. To get my hands dirty I followed this tutorial by Google using TensorFlow. The tutorial is a good introduction, but I wanted to see if I could take it a step or two further.
For one, use a larger dataset.
Two, the tutorial uses a smaller model than the hallmark "Attention is All You Need" paper.
This post summarizes my efforts to train a larger dataset on the original paramters of the model and tuning of the hyper paramters for better results.
1. A Larger Dataset
On his channel, Python Lessons, Rokas Liuberskis also works through the same TensorFlow tutorial. I found his detailed you tube playlist helpful and I wanted to mention here. The OPUS website he used is a great source of sentence pairs from many languages. They have some datasets topping 100M sentence pairs. Python Lessons wrote their own Custom Tokenizer. While I used the OPUS site to get a larger dataset, I stuck with the tensorflow tokenizer tutorial to tokenize the sentence pairs from OPUS.
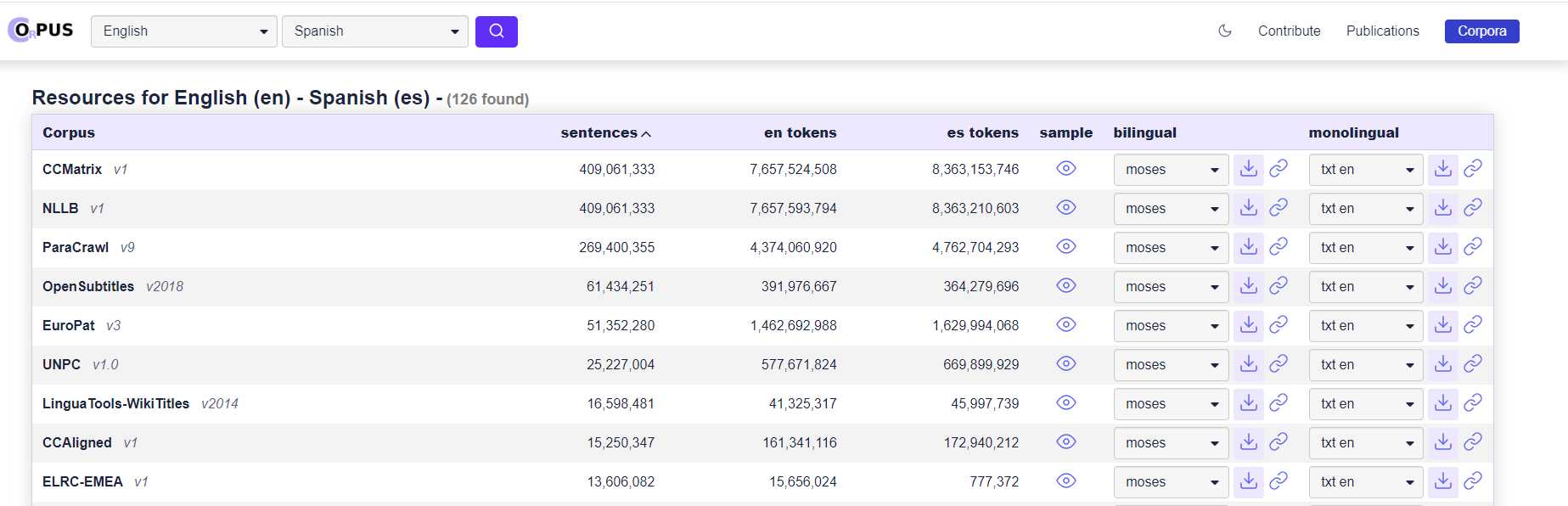
OPUS Language Datasets
This link gives all the English to Spanish datasets on the site. There are datasets of 400M sentence pairs. https://opus.nlpl.eu/results/en&es/corpus-result-table
I used the data from Wikipedia consisting of 1,811,000 english and spanish sentence pairs. https://object.pouta.csc.fi/OPUS-Wikipedia/v1.0/moses/en-es.txt.zip
Imports:
import numpy as np
import os
import tensorflow as tf
import tensorflow_text as text
Read the downloaded file and make es_data and en_data sets that are limited to a max length.
def read_files(path):
with open(path, "r", encoding="utf-8") as f:
data = f.read().split("\n")[:-1]
return data
#https://object.pouta.csc.fi/OPUS-Wikipedia/v1.0/mono/es.txt.gz
es_data_path = "datasets/Wikipedia.en-es.es"
es_data = read_files(es_data_path)
# https://object.pouta.csc.fi/OPUS-wikimedia/v20230407/mono/en.txt.gz
en_data_path = "datasets/Wikipedia.en-es.en"
en_data = read_files(en_data_path)
#Only use sentences that are at a max length
max_lenght = 500
dataset = [[es_sentence, en_sentence] for es_sentence, en_sentence in zip(es_data, en_data) if len(es_sentence) <= max_lenght and len(en_sentence) <= max_lenght]
#unzip the dataset back to get the filtered spansih and engish sentences for tokenizing below
es_data, en_data = zip(*dataset)
Build Vocabulary for the tokenizer
From the downloaded en-es.txt.zip build a subword vocabulary then tokenize it.
Following this google tutorial.
https://www.tensorflow.org/text/guide/subwords_tokenizer
Notes: You will need to save the Tokenizer from the tutorial. I made my own module and imported it here
# from the tutorial I saved the tokenizer in a .py file in my transformers module
from transformers import CustomTokenizer
Then I followed the tutorial using the OPUS dataset. First, set up the sub word tokenizer.
from tensorflow_text.tools.wordpiece_vocab import bert_vocab_from_dataset as bert_vocab
bert_tokenizer_params=dict(lower_case=True)
reserved_tokens=["[PAD]", "[UNK]", "[START]", "[END]"]
bert_vocab_args = dict(
# The target vocabulary size
vocab_size = 8000,
# Reserved tokens that must be included in the vocabulary
reserved_tokens=reserved_tokens,
# Arguments for `text.BertTokenizer`
bert_tokenizer_params=bert_tokenizer_params,
# Arguments for `wordpiece_vocab.wordpiece_tokenizer_learner_lib.learn`
learn_params={},
)
Then tokenize. Creating the tokens took 10-20 minutes.
#create Dataset's for tensorflow
es_dataset =tf.data.Dataset.from_tensor_slices([es_data])
en_dataset =tf.data.Dataset.from_tensor_slices([en_data])
def write_vocab_file(filepath, vocab):
with open(filepath, 'w') as f:
for token in vocab:
print(token, file=f)
es_vocab = bert_vocab.bert_vocab_from_dataset(
es_dataset.batch(5000).prefetch(2),
bert_vocab_args
)
en_vocab = bert_vocab.bert_vocab_from_dataset(
en_dataset.batch(5000).prefetch(2),
bert_vocab_args
)
You can see the tutorial by google for more details. I am just showing my steps here to create the tokenizer from a custom dataset and save it.
This is where I used the CustomTokenizer class from Google. Python lessons on his guide has his own implementation.
#save the vocab files
write_vocab_file('./datasets/es_wiki_vocab.txt', es_vocab)
write_vocab_file('./datasets/en_wiki_vocab.txt', en_vocab)
tokenizers = tf.Module()
tokenizers.es = CustomTokenizer(reserved_tokens, './datasets/es_wiki_vocab.txt')
tokenizers.en = CustomTokenizer(reserved_tokens, './datasets/en_wiki_vocab.txt')
model_name = './datasets/wikipedia_translate_es_en_converter_16k'
tf.saved_model.save(tokenizers, model_name)